Projects


-
What I Learned From Reviewing Hundreds of Conference Session Proposals
 I did not actually give anyone an A+. Nor did I get the chance to write “see me”.
I did not actually give anyone an A+. Nor did I get the chance to write “see me”.Since last fall, I’ve been pitching (and giving!) talks at tech meetups and conferences. So far it’s been an excellent way to hone ideas, meet new people, and learn more about the things I thought I knew. (Nothing like the stress of having to tell people what you know about something to make you really study up!)
This month, I marked an additional milestone: I was given the opportunity to be a conference session reviewer. I read hundreds of pitches over three categories for an upcoming conference, and what I learned about what makes a good session pitch both surprised me and didn’t.
-
Titles REALLY matter. I’m a sucker for a pun or just a clever title. A boring title, on the other hand, can prejudice reviewers against otherwise great content!
But a title that is clearly just pasted on also doesn’t work for me. I know there are people who decide up front that their talk is going to be, IDK, Avengers themed, and so they come up with a title that references the Avengers and then try to shoehorn their talk into the theme. Maybe some people are into that, but it’s not my thing.
-
There’s a sweet spot for submission length. Maybe about 300 words, including a bunch of bullet points? I saw presentation pitches that were one or two sentences long, and I saw presentation pitches that were so long they caused a major vertical scroll on an otherwise pretty compact review page. Too much information can actually be a negative.
-
Please, run spellcheck before you submit. I tried not to deduct points for submissions that contained spelling errors, grammatical mistakes and misplaced punctuation, because certainly people present differently than they speak, but it’s a pretty easy thing to fix and doesn’t reflect well.
-
Tailor your presentation to the venue! Many conference submission platforms let you store reusable talks. This is great and it can save you a ton of time to start from a non-blank page. But you shouldn’t just hit submit blindly. After copying the talk to your submission, make sure that it’s a fit for the specific RFC.
- Did you submit a day-long workshop for a conference only accepting 30-minute slots?
- Did you propose a frontend talk for a conference focusing on backend?
These examples are perhaps obvious, but there are less obvious ways your content might not be a fit (or could be a more obvious fit with some tweaking).
Let’s say you want to give a talk on hidden features in your favorite IDE. If the conference is Javascript focused, the examples you give in your bullet points should call out features that work with Javascript. If the conference is dev tooling focused, maybe you have examples that span languages (and you explicitly point out that your talk is language-agnostic).
These are small tweaks that shouldn’t take a long time when you’re putting together your proposal, but make it obvious to reviewers that you’ve thought about why your talk is a fit for this specific conference.
Another example: if the conference is language-agnostic, you need to sell us on why your talk on a specific framework is relevant now. But if you’re pitching a talk on React to React Conf, you probably don’t need to tell us why we should be using React.
-
A technical talk proposal doesn’t need to get so far into the nitty gritty at the proposal phase. The best ones I saw simply included the what (a language, framework or idea), the why (this language/framework/idea is more popular this year because of X), and a handful of takeaways, usually in bullet point form. Again, 300 words felt like the sweet spot.
-
It’s really difficult (I think) to pitch an advanced language-specific talk to a generalist conference! But if you do, you need to explain why people should attend your talk. Forget the conference attendees – the people reviewing your pitch might not be experts in the thing you’re pitching, so to even get accepted, you might need to include enough background information to get your reviewers up to speed!
-
I saw a handful of framings that kept popping up, some better than others.
-
Here’s how to get started with Thing. This can work, if you explain why attendees should want to get started with Thing.
-
7 mistakes I made trying to do Thing. Numbers in a title, as journalists will tell you, are always good. It doesn’t have to be 7. The mistakes help though.
-
Some Thing you thought was bad is actually good, and here’s why. This framing is catnip for me. I always want to hear how I’ve been thinking about things wrong.
-
What’s new with Thing You Already Know About since you last learned it. I saw a handful of talks with this angle at Frontrunners this winter and I’m so into it. I always learn something.
-
I built A Thing and intentionally limited myself to doing it the hardest/most oldschool way possible, to prove it can be done/demonstrate the benefits of some technology. This can be interesting but there’s only room for a few talks like this at a conference (IMO).
-
If you know Thing 1, here’s how to apply that knowledge to Thing 2. This is really hard to do at a generalist conference, because it presumes knowledge of Thing 1, but could work well at a conference that specializes in one language or framework.
This was such a rewarding experience getting to “peek behind the curtain” at what goes on during proposal selection, and I’m so glad I did it. Also, stay tuned for more exciting conference news from me soon :)
-
-
Partially Mocking a Class in Java
 This is an example of complete mocking, but not the kind of mocking this post discusses.
This is an example of complete mocking, but not the kind of mocking this post discusses.I love writing unit tests. i know this is an unpopular opinion but I just really like it. I love thinking of edge cases that could break code and then coming up with exactly how to create a test that will prevent that.
However, mocking everything stinks. Yes, we should be using in-memory fakes instead of mocks as much as possible, and I’ve been working toward this, but it is not realistic to make everything a fake.
My very smart coworker just alerted me to this method built into Mockito’s
whenmethod, which is used for controlling the behavior of mocks. If you want to stop reading now, just read the next two lines, and then you can go:when(thing.method()).thenCallRealMethod()This bypasses any mock behavior and goes back to the real class’s implementation. Handy!
For absolutely more details than you need, here’s an example:
class MyClass(){ public int myMethod(){ return 1; } } class SomeTestClass(){ public MyClass myClass = mock(MyClass.class); int result = myClass.myMethod(); assertEquals(1, result); }This contrived example will fail, because we haven’t explicitly declared the behavior of
myMethod. (It will returnnullinstead.)So what I would have done yesterday would look like this:
class MyClass(){ public int myMethod(){ return 1; } } class SomeTestClass(){ public MyClass myClass = mock(MyClass.class); when(myClass.myMethod()).thenReturn(1); int result = myClass.myMethod(); assertEquals(1, result); }This will work (ignore the part where this test is a tautology!), but if your method under test has a lot of external calls that you’re mocking out, this can get messy. That’s where
.thenCallRealMethod()comes in. If you had:class MyClass(){ public int myMethod(){ return 1; } public int someOtherMethod(){ return 3; } } class SomeTestClass(){ public MyClass myClass = mock(MyClass.class); when(myClass.myMethod()).thenReturn(2); when(myClass.someOtherMethod()).thenCallRealMethod(); int result = myClass.myMethod(); int result2 = myClass.SomeOtherMethod(); assertEquals(2, result); //true because we have mocked the behavior of this method assertEquals(3, result); //true because the real method returns 3 }Like I said: Handy!
-
What I Learned This Week: AI and Alt Text (Don't Do It)

For those of us who are sighted, it is easy to forget that alt text is a necessity for navigating the Internet for the millions of blind individuals who use screen readers. Not to mention, there are still, believe it or not, Internet users who do not load all images by default, whether to avoid some types of tracking or because their internet is spotty/unreliable. So if you’re reading this and ever work in the frontend, hopefully you are remembering to include alt text. (Thankfully, this blog generates its static files from Markdown, a language in which it’s easier to add alt text to images than not. But I’ll be the first to admit I could write better alt text.)
But isn’t writing alt text so much work? What if we let an AI write it for us?
Last week, my colleague gave an excellent presentation about the possibility of using AI to generate alt text. This is something that a number of websites are doing (see describeimage.ai, imageprompt.org/describe-image, aitools.inc/tools/ai-alt-text-generator, describepicture.org, and many, many others–I would assume that 99% of these are just wrapping an API call to ChatGPT).
I believe gen-AI tools are built into a number of CMSes as well. For example, here’s a blog post talking about how the edtech software Blackboard will flag images without alt text and offer to generate descriptions of the images, using Microsoft genAI tech.
However, the general consensus is that this tech is not yet ready to replace humans.
My colleague demoed a couple of images that are relevant to people who work in marketing. One of them was:
 We all know what this picture is, right?
We all know what this picture is, right?An AI alt-text generator described this as “a simple black checkmark on a white background,” whereas humans would probably prefer this to have the alt text “Nike logo” or simply “Nike”.
My colleague also showed a product image of a shampoo bottle on a beach. Since we work in marketing, our clients use a lot of product images! AI described this (fake) product image as something like, “A white bottle, labeled ‘shampoo’, standing upright on a sandy beach.” Better alt text would be the name of the product, like “Ocean breeze shampoo.”
Especially if the image is used as a clickable link (say in an email where you want people to buy the shampoo). If an image is used as a link, most (all?) screen readers will use the alt text as the link, so a long, flowery description is not useful here.
AI image descriptors also miss important cultural context, as shown in this article from UNC’s digital accessibility office, showing an example where a Maori dancer performing a ceremonial haka dance is described as “a person with his tongue out.”
That said, not every website does alt text well at this time. I found this exercise from Clark University’s “Introduction to Societal Computing” (what a wonderful class title, can I audit?) in which students are asked to compare AI-generated alt text and human generated alt text from three websites: a news site, a large nonprofit, and any third site. In the example given, the professor compares alt text on the New York Times’ website, Wikipedia, and Clark University’s own site.
I’ll let you read the outcomes for yourself but the TLDR is, unsurprisingly, large websites do a good job of writing descriptive alt text that generative AI cannot outperform, but smaller websites often have useless or no alt text, in which case a generative-AI-written caption might be a slight improvement. But there’s another way to improve alt text, which is to write it!
I couldn’t find a lot of takes on this topic from screen-reader users themselves. The general consensus seems to be that some (bad) alt text is better than no alt text.
However, I was hoping to find posts such as, “My favorite website went from having good alt-text to mediocre alt-text overnight, and I suspect they’re using AI”, or “My favorite website went from having no alt-text to mediocre alt-text overnight, and I suspect they’re using AI.” The lack of such takes leads me to think that this technology isn’t widespread enough yet for people to have noticed.
If a website’s images have no alt text, some screen readers and other software can still identify images, using their own built-in software. I believe this feature is built into new versions of the screen-reader JAWS, for example. But this software isn’t necessarily any better at identifying images, and can often be worse. Users report “hallucinations” and bugs, in the forums I found.
Supporters of AI-generated alt text say that if your choice is between literally no alt text (forcing users to rely on their own software, if they have it) and alt text written by a generative AI and approved by a human being, the latter is better. I guess that’s true, but only barely.
My take? As web developers, we can do better than outsourcing image descriptions to generative AI.
Resources
-
Don't Sync State, Derive It! (With Apologies to Kent C. Dodds)
 Syncing is for swimming, not for state.
Syncing is for swimming, not for state.This is a pretty standard lesson (Kent C. Dodds talks about it a lot in his React courses and on his blog) but it’s still something that has taken me a while to internalize.
With BookGuessr, I have a bunch of state!
I have the list of all books that could possibly be part of the game, the list of books that is part of the current game, the score, the high score, the game’s status (started or ended), and probably some other stuff. This is a lot to keep track of, and despite knowing what I know, my first draft of the app looked like this:
const [allBooks,setAllBooks]= useState(initialListOfBooks); const [chosenBooks,setChosenBooks] = useState([]); const [score, setScore] = useState(0); const [gameIsActive,setGameIsActive] = useState(false); ...and so on. Easy to write, not so easy to track.
Now, if a player chooses a book, we need to:
- remove that book from the list of available books
- add that book to the list of chosen books
- check if the score needs to increase, and increase it if so
- check if the game needs to end, and end it if so
That’s four separate state variables we need to manage! But we really only need to manage one state, if we turn our
allBooksvariable into something like this:[{'title': 'The Grapes of Wrath','author':'John Steinbeck','year':1939,'correct':true},{'title': 'Middlemarch','author':'George Eliot','year':1871},{'title': 'Snow Crash','author':'Neal Stephenson','year':1992,'correct':false}...]There are probably lots of ways to slice this, but this is the structure I have decided on (for now). Now,
scoreis calculated by performingallBooks.filter(book=>book.correct).length,chosenBooksare calculated by filtering on the same condition and sorting by year,gameIsActivecan be calculated by finding if any item in the array has theincorrectkey, and so on.This turns the above code into something more like:
const [allBooksForGame, setAllBooksForGame] = useState(allBooksWithDates()); const currentBook = chooseNextBook(allBooksForGame); const score = calculateScore(allBooksForGame); const highScore = calculateHighScore(score);This is pretty clean (the implementations of the helper functions I’ll leave up to the reader), but more importantly, when
allBooksForGamechanges, everything else updates without the programmer having to do anything. -
The Making of (and Redesigning of) BookGuessr
A couple of years ago, I got into my head the idea that I wanted to make a Wikitrivia style game with novels. I love to read, there’s a lot of publicly available data about books out there, why not? I made the first prototype in a weekend, using a list of 1000 Novels You Must Read from The Guardian, and data from The Open Library, and it worked, but.
I didn’t really want to show it to anyone because I really didn’t like how it looked, or behaved, and don’t even get me started on how it worked (read: didn’t work) on mobile.
Recently, I got a bee in my bonnet about redesigning it. I’d take another weekend and just spiff up the CSS and be done.
Lies, all lies.
First I spiffed up the CSS. I’m not at all a designer, so this was harder than it sounds. But I used a few tips from Erik Kennedy and I think I made it better.
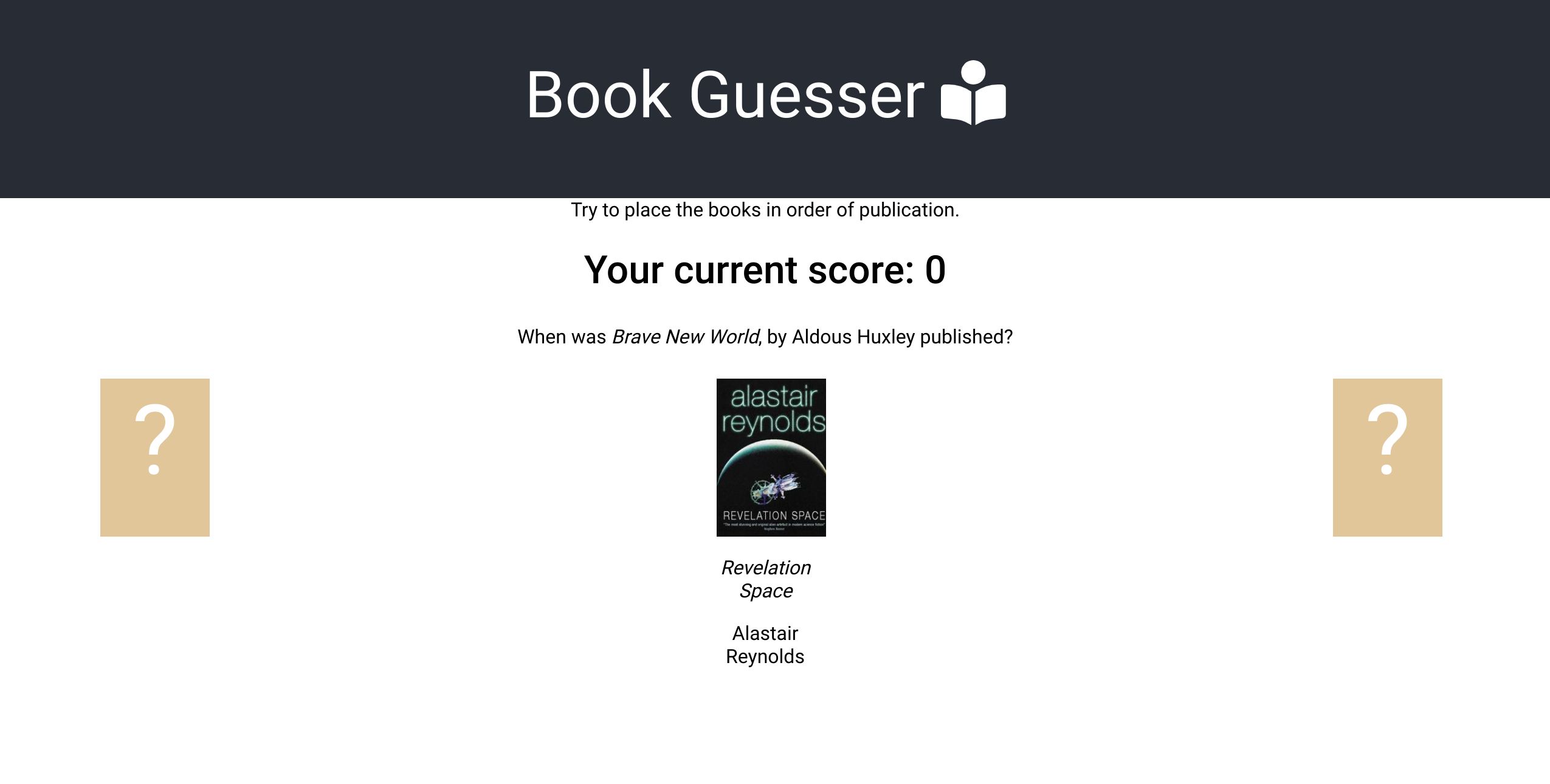 Before
Before After
AfterThen, because the mechanic of hovering over where you want to place a book is not just mobile-unfriendly but mobile-impossible, I remade the entire site using a drag-and-drop library. I chose React-DND-kit pretty much at random, and once I figured out its quirks, I can say I’m pretty happy with it, but there may be a future blog post forthcoming about all said quirks.
Then, because I was running into some annoying React off-by-one bugs related to state being set when I didn’t expect it, I ripped out all the game logic and redid that. (Future blog post coming: Don’t store state, derive it!)
This wasn’t a ton of coding work, but you know how side projects can drag on. So I’m happy to say, six months after thinking I’d just “take a weekend” to do a little cleanup, Bookguessr is finally ready for the world.
Until I get the itch to redesign it again. Which might be tomorrow.